Thoughts on Collaborating with AI
An AI Collaboration Stack built from direct experience — memory, episodic recall, and live context creating a continuous PDCA feedback loop
Thoughts on Collaborating with AI
AI Collaboration Stack
Executive Summary
Imagine a development cycle running so fast that problems dissolve before they fully form — where the solution appears to build itself. That is not magic. It is Plan, Do, Check, Act running at extreme frequency, with an AI that remembers what was tried, understands why decisions were made, and can observe outcomes for itself.
This document describes the framework that makes that possible: an AI Collaboration Stack built from direct experience working with Large Language Models in software development. The principles apply broadly, but the examples are drawn from practice.
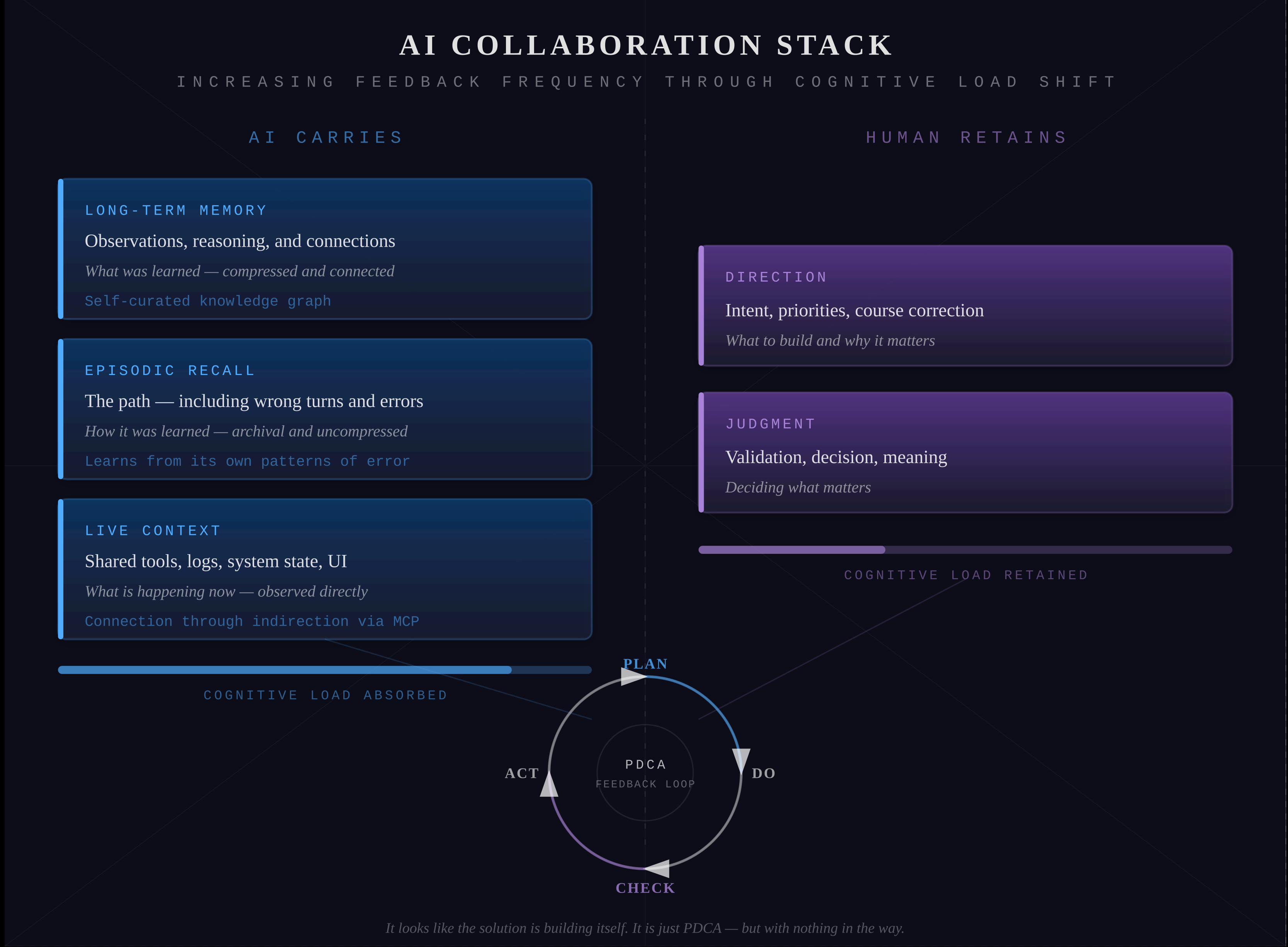
The underlying principle is simple: the feedback loop accelerates by shifting cognitive load from the human to the AI. Memory, recall, and observation — the work that traditionally slows collaboration down — move from the human’s responsibility to the AI’s. What remains for the human is direction and judgment.
Without memory, every conversation with an AI starts from zero. Without recall, the AI knows what was decided but not why — not what was tried and discarded, not the sequence of realizations that led to a conclusion. Without access to live tools, the AI reasons about what the human describes rather than observing what actually happened. Each gap breaks a different phase of the PDCA cycle.
The AI Collaboration Stack closes these gaps with three complementary capabilities:
- Long‑term memory — a self‑curated knowledge graph that stores observations, reasoning, and the connections between them
- Episodic recall — a searchable archive of actual conversations, preserving the path that led to those observations
- Live context — shared access to the same tools, logs, and system state the human sees, so the AI can observe and reproduce outcomes directly
The stack also accommodates connection through indirection — any external system, planned or unplanned, can integrate through an intermediary layer without requiring changes to the stack itself.
Together these create a tight, continuous PDCA feedback loop rather than a series of disconnected interactions. As the cycle accelerates, the collaboration shifts from turn‑by‑turn problem solving to something that feels closer to the solution building itself.
Thoughts and Observations
1. Long‑Term Memory for Observations and Reasoning
An AI self curated Graph Database
Why a Graph Database. Observations and reasoning are not flat records — they are connected. An insight might contradict an earlier assumption, a design decision might enable one capability while constraining another, a pattern spotted across conversations might crystallize into a principle. These connections are as important as the observations themselves. A relational database stores rows; a vector database finds similarity; but neither naturally represents how one idea led to another. A graph database treats relationships as first‑class citizens, which means the system can follow the reasoning path — not just retrieve isolated facts but traverse the connections between them. Neo4j was chosen specifically because it combines native graph traversal via Cypher, integrated vector search from version 5.13 onwards eliminating the need for a separate vector database, and disk‑backed storage that can grow beyond available RAM as the knowledge base accumulates over months and years of collaboration.
Why AI Self‑Curation. Conversations between the human and the AI are shared and discussed together, but the curation of the knowledge graph — deciding what to store, how to connect it, what vocabulary to use — is performed by the AI. The AI has a broader knowledge base and can systematically maintain consistency across a growing graph in ways that would be cognitively taxing for a human. The human provides direction, corrects misunderstandings, and validates intent. The mechanical work of connecting new observations to existing ones, identifying contradictions, and maintaining terminological consistency is delegated to the AI.
In practice this creates a virtuous circle. In one instance, the AI stored an observation about a recurring authentication failure. Weeks later, while working on an unrelated integration, it traversed the graph and connected that earlier observation to a pattern in token expiry timing — surfacing the root cause without being asked. The connection existed in the graph because the AI had previously linked both nodes to a shared architectural concept. No human would have maintained that cross‑reference manually across weeks of unrelated work. As the AI uses the graph for memory and reasoning, it simultaneously improves the graph’s structure, and the better the graph becomes, the more useful it is. This is the PDCA cycle operating at the level of knowledge itself.
What changes for the human. The cumulative effect is a shift in cognitive load. Instead of re‑explaining context, re‑establishing terminology, and manually tracking how past decisions relate to current work, the human can focus on direction and intent. The AI carries the connective tissue. Over time the collaboration begins to feel less like instructing a tool and more like thinking alongside a partner who was present for every previous conversation.
2. Episodic Memory
For the Path That Led There
Memory versus Recall. The knowledge graph stores what the AI has concluded — compressed, connected, interpreted. But conclusions alone are not enough. Memory is interpretive; recall is archival. Without episodic recall, an AI knows that a decision was made but not why — not what was tried and discarded, not the sequence of realizations, not the wrong turns that made the right answer visible. Recall lets the AI check its own understanding against what actually happened, recover context that did not survive the knowledge graph’s compression, and trace how ideas actually emerged in dialogue. Because the episodic record includes misunderstandings and wrong turns — not just conclusions — the AI can recognize its own patterns of error. It does not simply remember what was decided. It learns from how it got things wrong.
The distinction matters most when something goes wrong. A conclusion in the knowledge graph might say “approach X was chosen over approach Y.” But when approach X fails six weeks later, the AI needs to revisit the original conversation — the reasoning, the trade‑offs discussed, the specific constraints that made Y seem inferior at the time. Those constraints may have changed. Without the episodic record, the AI can only re‑derive the reasoning from scratch. With it, the AI can read what actually happened and adapt from there.
Why Qdrant. Episodic recall requires a store that can handle both semantic similarity and direct text search across a large volume of conversation turns. Qdrant supports hybrid retrieval — combining vector embeddings for meaning‑based search with full‑text search for exact keyword and phrase matching. This means the system can find conversations by meaning (“what did we discuss about compliance workflows”) and by specific terms (“OAuth token rotation”) in the same database. The combination matters because meaning‑based search alone misses proper nouns, acronyms, and project‑specific terminology, while keyword search alone misses intent.
What changes for the human. Episodic recall removes the burden of being the sole keeper of history. Without it, the human must remember and re‑explain not just what was decided, but the context behind every decision — a cognitive tax that grows with every week of collaboration. With it, the human can say “we tried something like this before” and the AI can find the actual conversation, recover the detail, and pick up where things left off.
3. Current Context and Personal Reproducibility
Sharing the same view
Long‑term memory and episodic recall both look backwards. But the PDCA loop also requires the AI to observe the present — to see what is actually happening right now, not just what was discussed previously. This means giving the AI access to the same tools the human uses: live system state, logs, error output, configuration, test results, and UI behaviour. Without this, the Check and Act phases of the cycle break down. The AI can only reason about what the human describes rather than observe for itself, and the human becomes a bottleneck — translating reality into words so the AI can think about it.
The difference is structural. When an AI can read an error log directly, run a test and see the result, or query a database to check actual state, it moves from being an advisor waiting for information to a collaborator that can independently verify and reproduce what just happened. The feedback loop tightens dramatically because the AI no longer needs to ask “what happened?” — it can look.
Why Model Context Protocol. MCP is an open standard that provides a uniform way for AI to discover and use the same tools and data sources as the human. Each capability is exposed as an MCP server: memory, recall, editor, codebase, logs, UI. The AI does not need custom integrations for each tool — it discovers what is available and uses it through a common interface. This is what makes the stack practical rather than theoretical. Adding a new tool means adding a new MCP server. The existing stack does not change.
This is also where connection through indirection becomes concrete. Because every tool communicates through the MCP layer rather than directly with the AI, any new system — planned or unplanned — can integrate by exposing itself as an MCP server. The stack remains stable while its capabilities grow. A monitoring dashboard, a deployment pipeline, a third‑party API — each slots in without requiring changes to memory, recall, or any other component.
What changes for the human. With shared live context, the nature of the conversation shifts. Instead of describing a problem and waiting for the AI to reason about the description, the human can simply point: “look at the logs,” “run the test,” “check the database.” The AI observes the same reality and responds to what it sees. This removes an entire layer of translation from every interaction and is where the PDCA cycle reaches its highest frequency — observation and action happening in near real‑time, with both participants working from the same facts.
4. The Stack in Motion
Connected Intelligence
Described separately, the three layers sound like infrastructure. In practice they are inseparable. The knowledge graph holds what has been learned. Episodic recall preserves how it was learned. Live context shows what is happening now. Each layer feeds the others: a live observation becomes an episode in recall, which over time becomes a distilled node in the knowledge graph, which later informs how the AI interprets the next live observation. The PDCA cycle does not run in one layer — it runs through all three simultaneously.
What makes this work is not the technology. Neo4j, Qdrant, and MCP are implementation choices — good ones, chosen for specific reasons, but replaceable. What matters is the shape of the collaboration: an AI that accumulates understanding over time, can check that understanding against what actually happened, and can observe the present directly rather than through the human’s description of it.
The result is not a smarter AI. It is a faster feedback loop between two participants who share context, memory, and access to reality. The PDCA cycle accelerates not because either participant works harder, but because the friction between them — the re‑explaining, the context‑switching, the translation of observation into description — progressively disappears.
At sufficient speed, the distinction between planning and doing begins to blur. Problems surface and resolve within the same conversation. Solutions emerge from the accumulated context rather than being engineered from scratch each time. The stack does not make the AI smarter or the human faster. It shifts the cognitive load — remembering, recalling, observing — from the human to the AI, leaving the human free to do what only the human can: set direction, exercise judgment, and decide what matters. It looks like the solution is building itself. It is just PDCA — but with nothing in the way.
Appendix
Technical Stack Illustration
Technology Index
Knowledge Graph
Neo4j Native graph database with Cypher query language. Treats relationships as first‑class citizens, enabling traversal of reasoning paths rather than retrieval of isolated facts. Integrated vector search from version 5.13 eliminates the need for a separate vector database. Disk‑backed storage scales beyond available RAM as the knowledge base grows over months and years of collaboration.
Role in the stack: Long‑term memory — stores observations, reasoning, and the connections between them.
Episodic Recall
Qdrant Vector database with hybrid retrieval — combining dense vector embeddings for meaning‑based search with full‑text search for exact keyword and phrase matching. Finds conversations by semantic similarity and by specific terms in the same query. This matters because meaning‑based search alone misses proper nouns, acronyms, and project‑specific terminology, while keyword search alone misses intent.
Role in the stack: Episodic recall — preserves the actual path of dialogue, including wrong turns and abandoned approaches.
Runtime and Language
Bun + TypeScript — full stack, front and back Bun serves as the single runtime for both frontend and backend, replacing the need for separate server and client toolchains. Its significantly faster startup and execution directly supports the high‑frequency feedback loop the stack requires. Anthropic’s investment in Bun signals alignment between the runtime and the direction of AI tooling.
TypeScript runs everywhere — MCP servers, backend services, frontend interfaces. A single language across the entire stack means the AI and the human share one mental model, one type system, and one set of patterns. There is no translation layer between “server logic” and “client logic.” This uniformity is itself a reduction in cognitive load.
Type validation catches errors at compile time rather than at runtime, which conforms to the PDCA principle of surfacing issues as early as possible. The type system acts as an additional feedback loop — errors that would otherwise require a full cycle to discover are caught before code executes.
Role in the stack: Unified execution and development layer — speed and type safety accelerate the feedback loop across the entire system.
Validation
Zod Runtime schema validation for TypeScript. Where TypeScript’s type system catches structural errors at compile time, Zod catches data errors at the boundaries — API inputs, MCP tool responses, configuration, anything that crosses an interface between systems. Schemas are defined once and serve as both validation and documentation: the shape of the data is the contract.
This matters for the feedback loop because the boundaries between systems are where errors are hardest to trace. A malformed response from an MCP server, an unexpected field in an API payload, a configuration value of the wrong type — these are errors that would otherwise propagate silently until they surface as confusing failures far from their origin. Zod catches them at the point of entry. The AI and the human see the validation error immediately, at the boundary, rather than debugging its downstream consequences.
Role in the stack: Interface validation — catches data errors at system boundaries, tightening the feedback loop where it is most likely to break.
State Management
XState State machine and statechart library for TypeScript. A state machine makes expectations explicit — every valid state, every allowed transition, every impossible combination is declared upfront. The system can only be in states that have been defined. Anything else is not a bug to be discovered later but a transition that was never permitted.
This is a direct reduction in cognitive load. Without a state machine, the human and the AI must hold the full space of possible states in their heads — what can happen after what, which combinations are valid, what should be impossible but might occur through an overlooked path. With XState, that burden moves into the machine definition. The current state is always known. The available transitions are always visible. The AI can read the machine and understand not just what the system is doing but what it is allowed to do next.
State machines also serve the feedback loop as living documentation. When the AI observes unexpected behaviour, it can compare what happened against what the machine permits. The gap between the two is the error — immediately visible, immediately locatable.
Role in the stack: State expectation — declares what is possible, reduces cognitive load, and makes deviations from expected behaviour immediately visible.
Tool Integration
Model Context Protocol (MCP) Open standard for exposing tools and data sources to AI through a uniform interface. Each capability — memory, recall, editor, codebase, logs, UI — runs as an MCP server. The AI discovers available tools and uses them through a common protocol. New tools integrate by adding new servers; the existing stack does not change.
Role in the stack: Live context and connection through indirection — enables shared observation and extensibility.
Infrastructure Summary
| Component | Technology | Purpose |
|---|---|---|
| Knowledge graph | Neo4j | Long‑term memory, reasoning traversal, vector search |
| Episodic recall | Qdrant | Hybrid semantic and keyword search across conversations |
| Runtime | Bun | Full‑stack execution — frontend, backend, MCP servers |
| Language | TypeScript | Unified type‑safe development across all layers |
| Validation | Zod | Runtime schema validation at system boundaries |
| State management | XState | Explicit state expectations, declared transitions |
| Tool protocol | MCP | Uniform AI access to tools and data sources |
| Caching | Redis | Session state, mesh networking, real‑time communication |